The origins of much of ancient literature is veiled in mystery. There are countless texts that are ascribed as ‘date unknown, author unknown,’ leaving no clue as to when, where or who wrote them. It goes without saying that a better understanding of the context behind their formation would likely yield a deeper understanding of the text. The subject of this research — the Vedic ritual literature of ancient India, said to be composed between 1500 and 500 BCE — is one example of this.
The Vedas collectively refer to a number of classical texts created by religious devotees — the so-called Brahmins — around the faith of the Indo-Aryan peoples, who invaded India beginning in 1500 BCE. Their religion consisted of communing with many gods, centered around those in nature, through praising them and bringing offerings for them into fire and benedictions made for prosperous relations between man and nature. This religion was the origin of Hinduism, the religion that represents Indian society throughout its history. The Vedic texts have been passed down through an oral tradition (They have been passed down through transcription of text after the written word spread throughout India; however, the oral passing down of the text has been at the core of the tradition.) with a variety of retellings unique to each of several lineages (or schools of thought). The Vedic texts passed down by each school consist of praise to gods and ritual benedictions — the oldest of the texts — with commentaries on rituals, philosophical discussions, and ritual details added later on to gradually create a body of literature over a long compilation period. In essence, the Vedas are multiple texts compiled by the various schools, which connected with each other, that is the horizontal axis, and in the shifting trends of the times, that is the vertical axis of time. Thus, we can position the composition and development of the Vedic texts against a vertical axis of time representing chronology and along a horizontal axis representing the geographical changes that occurred to these various schools or social groups — being situated in the north of ancient India — as well as the changes to their interconnectivity.
It’s believed that ancient Indian society of the time shifted from tribal, nomadic peoples to form small city-states. The goal of this project is to explore the development of ancient Indian society through the chronological and geographical positioning of the Vedas.

Data science + Ancient Indian literature
There is an existing body of research in the field of Indian Studies (Vedic Studies) that examines the philosophy, rituals or linguistic phenomena appearing in the Vedas and considers the differences across schools of thought and transitions over time. By introducing the methodology of data science to this category of research, the scale of what can be examined can be expanded, more detailed analyses can be performed, and more complex changes and relationships can be considered. We expect to obtain various types of analysis results through investigation of the complex text formation process of the Vedas, in relation with relevant geographical and chronological features through multiple information science perspectives.
Rather than being completed all at once, the Vedas can be taken as comprising multiple linguistic layers, with additional portions gradually added to the central text. This necessitates an analysis of the linguistic layers in one of the texts, thereby allowing a further comparison by linguistic layers across multiple texts. The cross-textual comparison will be a comparison of texts believed to be from the same era, as well as will allow for a consideration of the confluent relations of texts from differing eras.
By developing a system of “visual analytics,” in which various features are visualized interactively, it becomes possible to present an overview of the chronological and geographical features in the ancient Vedic corpus, something that individual analysis fails to achieve. We aim to integrate Indian studies with visual analytics that is the science of analytical reasoning facilitated by interactive visual interfaces. While this spatiotemporal literature mapping will be, itself, one result of this research, it will also serve as a departure point for deeper discussions into the development of ancient Indian society.
Research Method and Team
Our research primarily focuses on the analysis using natural language processing techniques and the development of data visualization system. This is supported by the creation of morphological analysis data from Vedic literature. Furthermore, based on the results of these studies, we are collaborating with Oliver Hellwig on the development of a dating estimation program.
The analysis using natural language processing techniques is constantly evolving with the remarkable progress in this field, and we continuously incorporate new methodologies. This part is handled by young researchers, So Miyagawa, Yuki Kyogoku, and Yuzuki Tsukagoshi. Using tools such as Word2Vec, Doc2Vec, Transformers, Stylometry, and Text Reuse Detection, we primarily analyze the language of Vedic literature, focusing on vocabulary. By conducting similarity analysis, dividing chapters within the literature, we examine the internal structure of the literature and further analyze multiple texts to reveal the relationships between them.
The development of visual systems with an emphasis on data visualization is undertaken by Hiroaki Natsukawa and Kyoko Amano. As a system for visualizing the relationships between literature, we have developed a visualization tool that utilizes an index covering the presence of mantras (ritual formulas) used in rituals across different texts. This tool can be used online and is publicly available at: http://ancient-india.natsukawa-lab.jp/
* Bloomfield, Maurice (1893): A Vedic Concordance. [Harvard Oriental Series 10]. Cambridge – Mass. In this research, an expanded version (with electronic data) was used for this purpose: Franceschini, Marco (2007): An updated Vedic concordance : Maurice Bloomfield’s A Vedic concordance enhanced with new material taken from seven Vedic texts. Cambridge: Dept. of Sanskrit and Indian Studies, Harvard University.
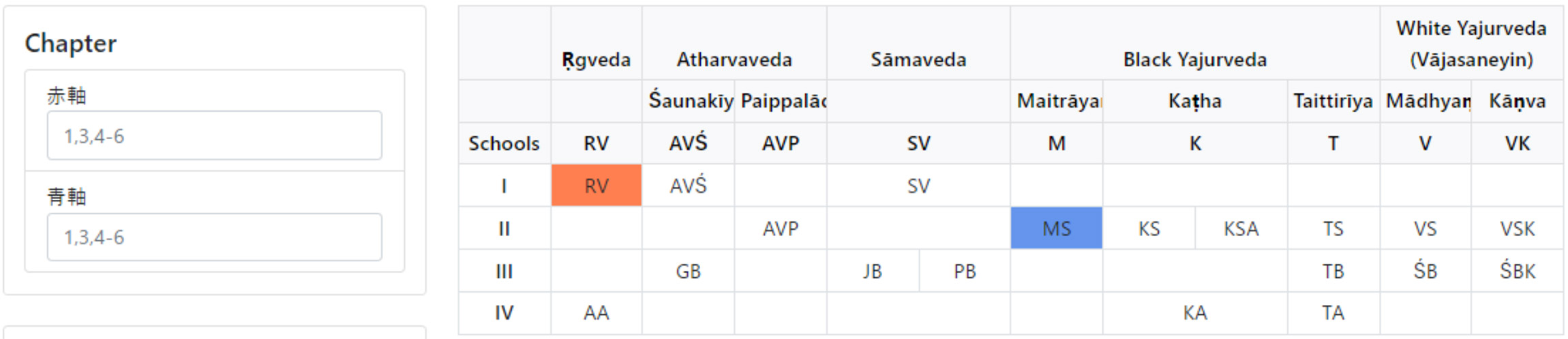
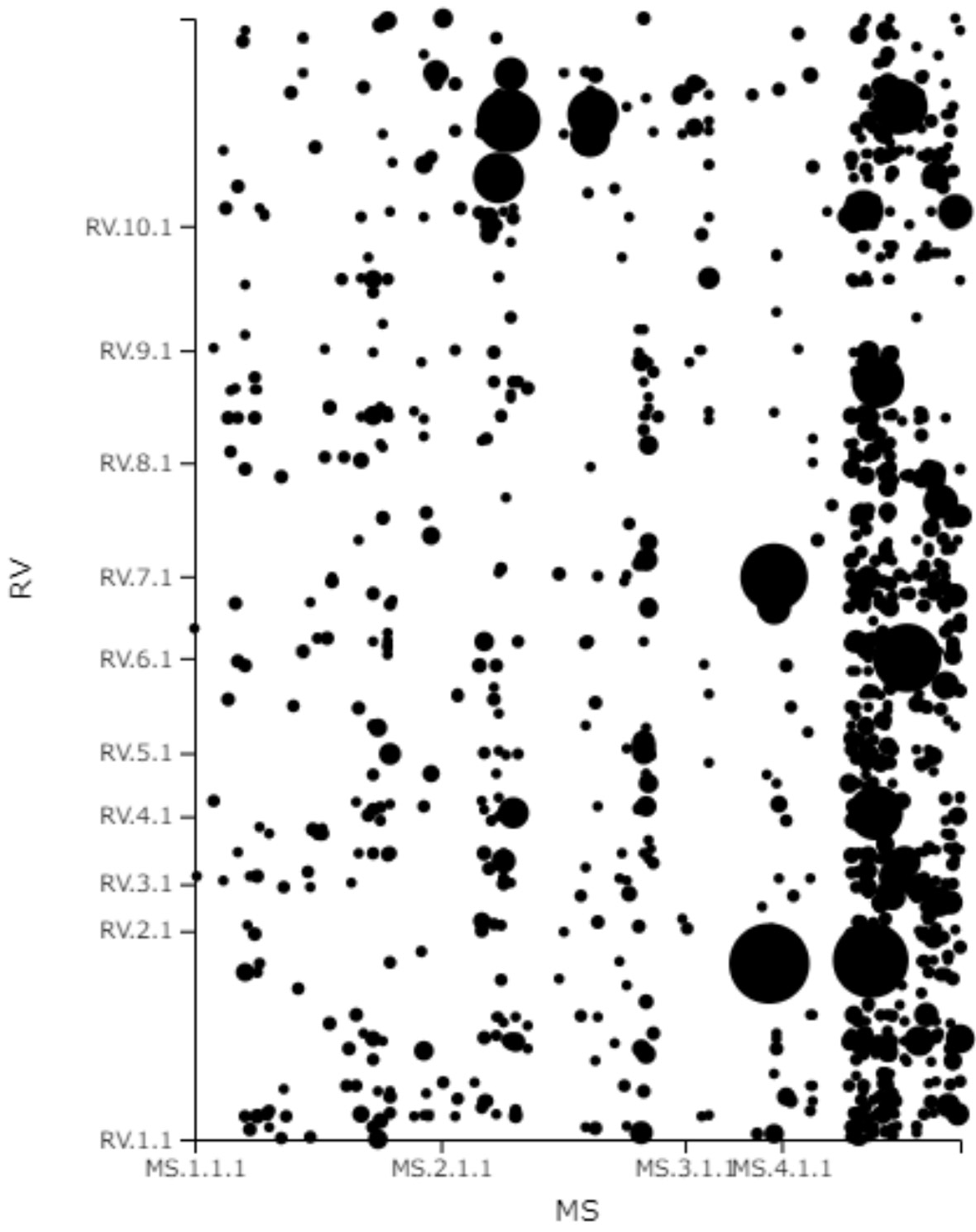
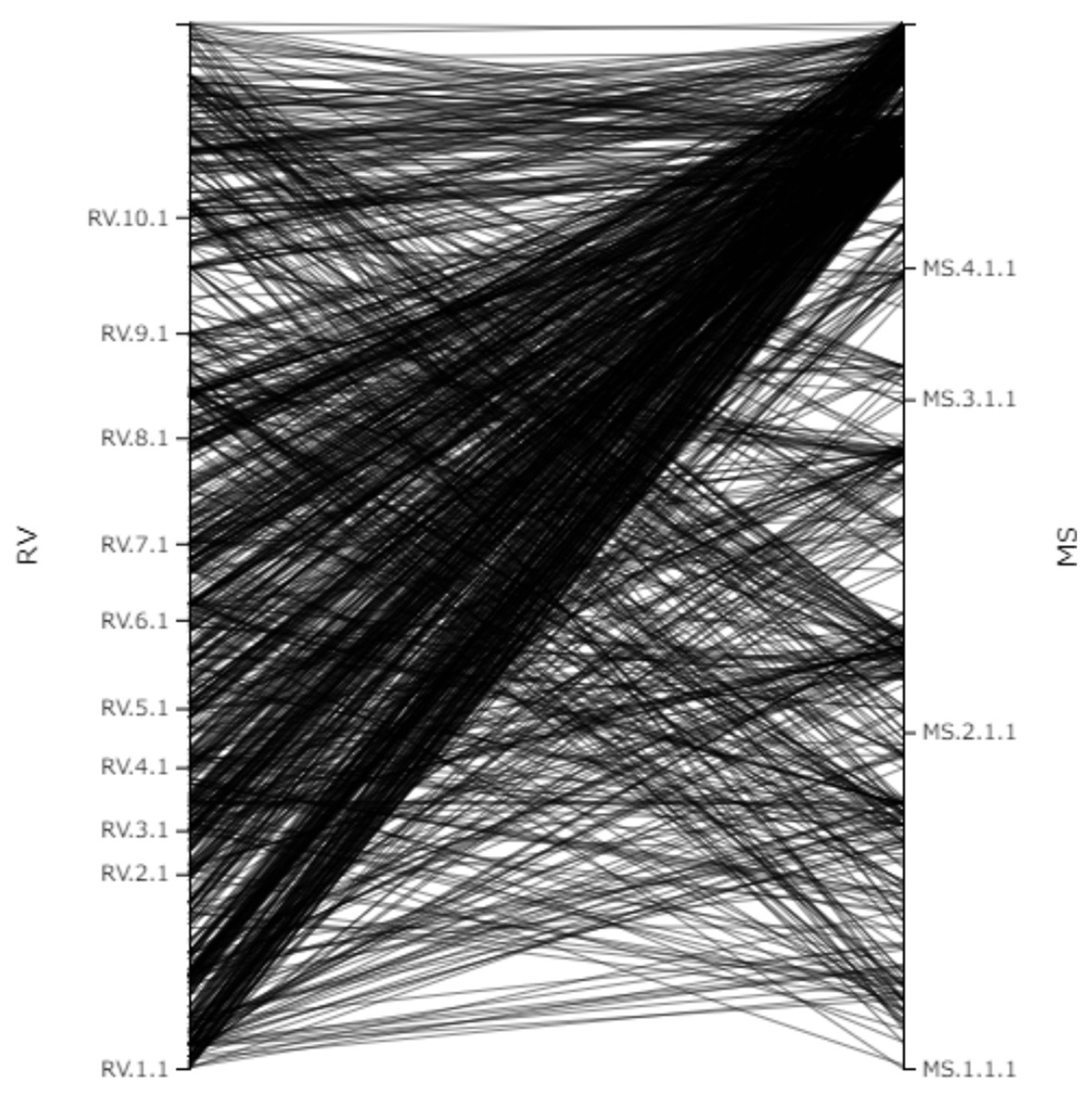
In this system, you can select two references from a table that categorizes Vedic literature by school and period, and display their relationship. You can also input a specific chapter in the left “Chapter” box to display only that particular chapter. The relationship between the references is represented by two types of graphs: scatter plot and parallel plot. These graphs allow you to examine which parts of one reference are closely related to which parts of the other reference. The graphs can be exported as data in PNG format.
On the left side of the page, there is a list of rituals described in the literature. If you want to explore the relationship between the references for a specific Vedic ritual, you can select and display only that particular ritual. The numbers written after the ritual names represent the count of mantras included in that chapter that co-occur in the chosen two references. This information is also visually represented by stacked bar graphs overlaid on the ritual names. The total count of co-occurring mantras is indicated after “ALL.”
From the statistical analysis based on mantra co-occurrence, we are also exploring other data visualization methods. We aim to visualize not only the relationships between literature but also the internal structures of each individual reference, enabling deeper insights through visual representation.

Another challenge in the data visualization part is the development of a system that visualizes the images researchers have when reading literature. It involves representing a literatre as a map and marking landmarks on it. By creating a visualization system that closely resembles the mental images researchers create when contemplating the content and composition of literature, we hope to facilitate in-depth reading, discussions, and sharing of ideas, across various literary genres and works.
Supporting these analyses and tool development is the morphological analysis data of Vedic literature created by Makoto Fushimi and Kyoko Amano, using Oliver Hellwig’s tagging system for grammatical analysis. The data creation process started under the research project ” Construction of Database for Quantitative Analysis of Language with a View to Clarify the Process of Composition of the Ancient Indian Literature,” funded by JSPS KAKENHI challenging research (Preliminary Research) Grant Number: 20K20697, from 2020 to 2022, and it has been continued within this project. Achieving accurate morphological analysis and data compilation requires manual checks by specialists in Vedic literature, which is time-consuming. We plan to complete the data for the central targets of this research project, namely Maitrāyaṇī Saṁhitā, Kāṭhaka-Saṁhitā, and Taittirīya-Saṁhitā, within the project duration. The created data will be stored in the DCS – Digital Corpus of Sanskrit (http://www.sanskrit-linguistics.org/dcs/index.php).
Through the establishment of this database and the exploration of the formation and correlations of literature, we are collaborating with Oliver Hellwig’s project, “ChronBMM – Bayesian Mixture Models für die Datierung von Textkorpora”. We provide evaluation and suggestions for model improvement to support the development of the ChronBMM project’s dating estimation program, which includes Vedic literature and other ancient texts.
For more information on ChronBMM, as well as the website of the Digital Humanities project by the German Federal Ministry of Education and Research, please visit the following links:
https://chronbmm.phil.hhu.de/
https://www.geistes-und-sozialwissenschaften-bmbf.de/de/Digital-Humanities-1710.html